









If you wish to learn web scraping, I highly recommend Scrapy because it is truly an amazing framework. I really have to say kudos to Scrapinghub for the job well done.
AWS is also amazing... but at times so confusing. It's not always simple to grasp everything.
In this short post, we'll go through the entire setup process to get you scraping quickly.
At the end of this post, you will have:
- A running instance of scrapyd on AWS EC2
- SSL setup with a load balancer
If you do not know how to scrape a website, check out this post.
Setting up the EC2 Instance


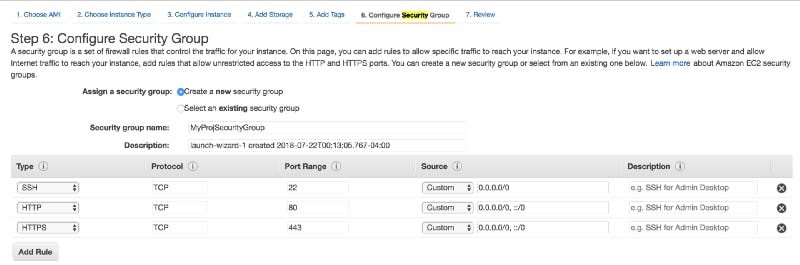
The security group setup is important!
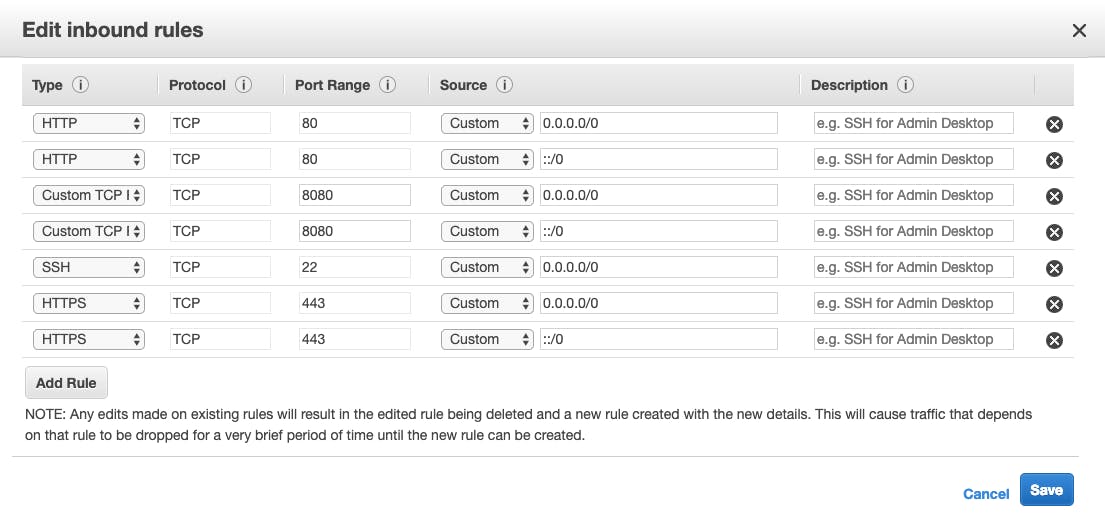
Don't forget to add the port 8080 on the inbound rules, otherwise it won't work:
Verify you can ssh to the instance.
Update packages.
Install Git.
Clone your repo with git clone (use an HTTPS URL instead of git@).
Install Docker.
Start the Docker service.
Add the ec2-user to the docker group so you can execute Docker commands without using sudo.
Check that the new docker group permissions have been correctly applied by exiting the instance and ssh again, then:
If you're getting permission denied try logging out of SSH and login again.
Install docker-compose.
Apply executable permissions to the binary.
Create the .env file for your production environment variables.
Your .env file will look something like this:
You'll need a YML file:
If you do not have a docker image, here's one, courtesy of Captain Data:
Use the following script to run the container behind NGINX (which we highly recommend):
This way, you're protecting your scrapyd instance with basic authentication. The setup uses the environment variables USERNAME and PASSWORD that you setup in the .env.
Launch the Docker container.
Setting up the Elastic IP Address
Go to Elastic IPs on the left side panel in your console.
Click on Allocate new address.
Then Associate address in the upper dropdown menu Actions.
Setting up SSL
Click on Services, search ACM and click on Certificate Manager.
Click Request a Certificate (a public one) and add your domain scrapy.example.com.
Choose DNS validation (way faster).
Add the CNAME record on your provider (Route53, GoDaddy, OVH, Kinsta or any other) and hit Continue.
Once the validation is ready, you will see a green issued status.
If you're having trouble while setting up the SSL certificate,check out this guide.
Setting up the Load Balancer
A load balancer makes it easy to distribute traffic from your site to the servers that are running it.
Go to Load Balancers (from EC2) on the left side panel in your console and Create Load Balancer.
Choose Application Load Balancer (HTTP/HTTPS, the first one) and hit Create.
Then, add the zones you wish to use (below Listeners).
Hit Next and Choose a certificate from ACM and select the one you previously created.
Next and select the security group we created in the first step.
Next and create a Target Group by just adding a name to it.
Next and select the instance and Add to registered on port 8080. Make sure the port is 8080 (the value next to the button).
Review and Create. You'll be redirected to the Load Balancers view. Select the load balancer you created, and Add a Listener with a port value of 80 and forward to the Target group we just made (ignore the red warning).
This should already be the case.
And... tada! That's all for today 😀
You're now able to push your scrapy project to your scrapyd instance on EC2. Consider using scrapyd-client to do so.
Don't hesitate to ping us if we made a typo or if something is not up-to-date.
And if you don't want to manage your own scraping architecture, give Captain Data a try.
{{tech-component}}



